This is my summary of HasGeek Open House conference on Building Data Products at Uber, by Hari Subramanian held on 15th this month.
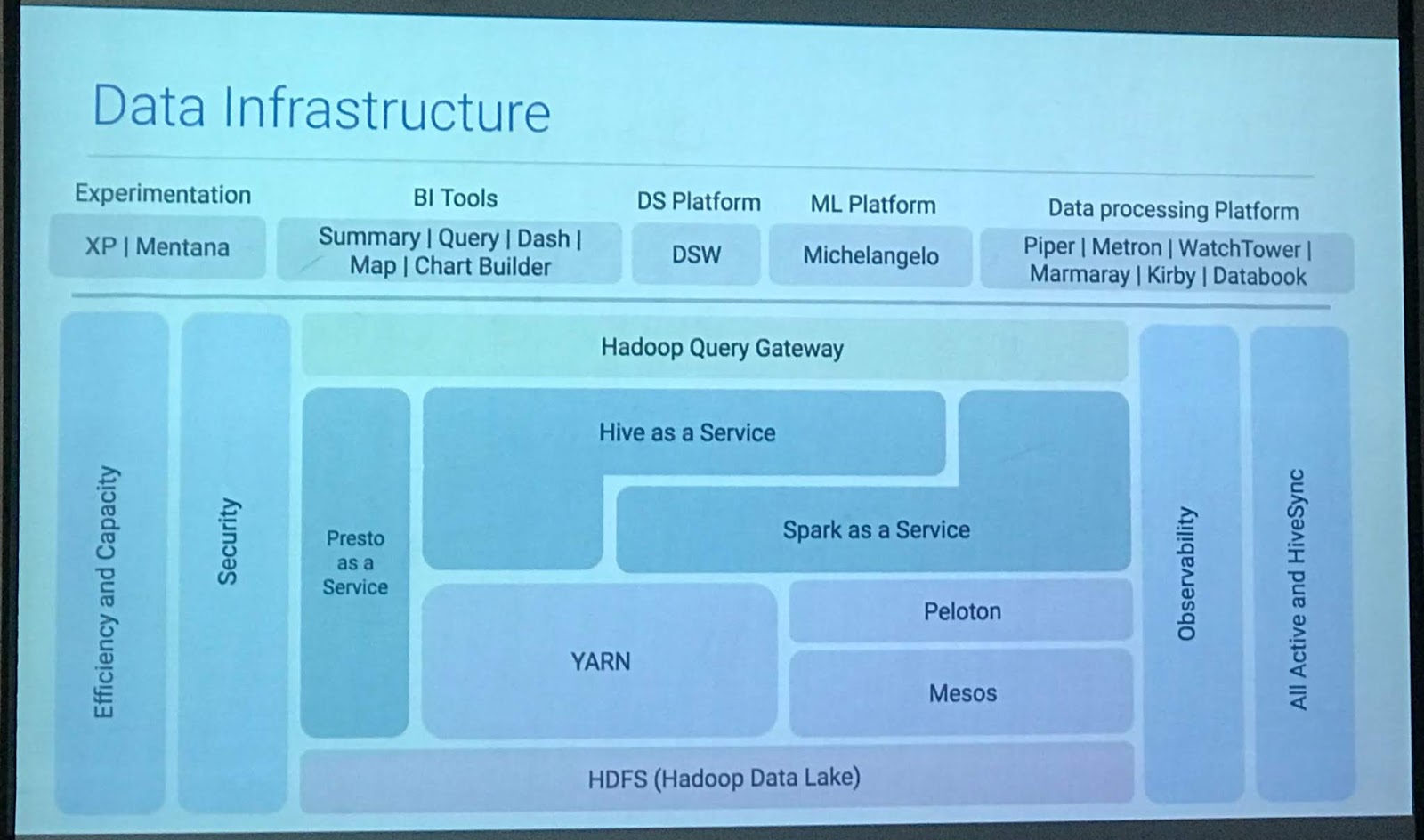
- Data size is in petabytes.
- Results found in staging is not quite the same when using the same model in production due to various factors.
- For deep learning, TensorFlow is used. Results found in AWS and GCP are different.
- They have build their own BI tools for visualisation.
- Hive is extended in-house. Hive and Spark overlaps to a certain extend. There are few map-reduce jobs still used which is why Hive is used.
- Uses own data center.
The talks was a high level overview of how Uber uses ML.